An Unexpected Benefit of Eating my Own Dogfood

"Eating your own dogfood" forces you to address data format migration early in a software project and treat data migration as an essential feature of the application. This can turn out to be a very useful capability.
When GitHub introduced their new issue tracker they removed the feature I found most useful: absolute ordering of issues. So I wrote my own tracker tool called Deft. Deft is a simple tool that addresses one bugbear I have with every enterprisey issue tracker I've ever used: prioritisation. Deft gives all issues a status, and within each status stores items in strict priority order. There's no way in Deft to give issues ambiguous priorities. You can easily change the status of an issue, to reflect the progress of development and deployment, and can change its priority, which shuffles up or down the priority of all other issues with the same status. You can give items a detailed description and some machine-readable properties, and that's basically it. One of my goals in writing Deft was to make it do as little as possible and still be useful for me.
As soon as Deft had basic functionality, I used it to keep track of its own features. That meant I had to implement data format versioning and migration very early in the project, long before I packaged it up for public release. Deft refuses to run against a database that has an incompatible format version, so that it doesn't corrupt the data, and can automatically upgrade any prior version of the database to the latest format.
This upgrade mechanism had an unexpected benefit.
Deft does not keep track of history itself. The database is made up of simple text files that are stored alongside a project's code in the version control system. I can pull historical data out of the version control system to analyse how the project has progressed over time and generate statistics and visualisations. For example, here is a Cumulative Flow Diagram generated by Deft that shows progress on the Deft project itself.
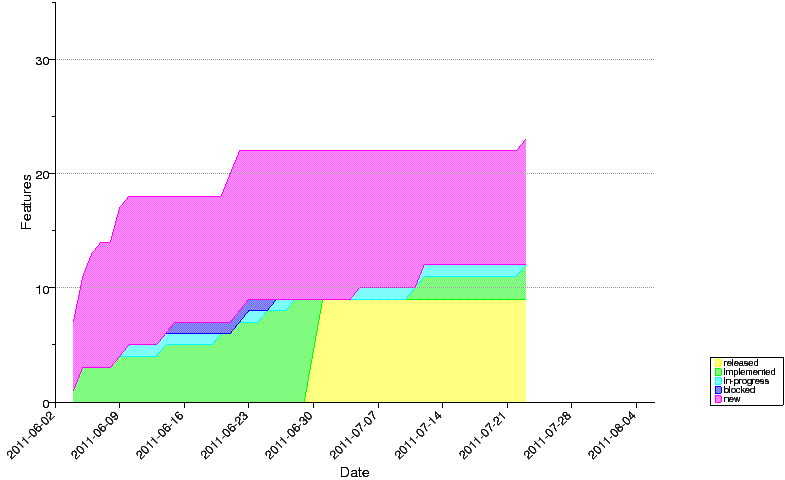
My initial implementation of historical analysis read the Deft database directly from blobs in the Git repository. But when I went too far back in the project's history the tool crashed. I'd neglected an obvious fact: old revisions in the Git repository record the Deft database in obsolete formats that the latest version of the tool no longer supports. Building a tool on top of a version control system does not give you a historical database for free.
To perform historical analysis, the tool must be able to read every version of its data format. It's a significant effort to maintain code to load all versions of a data format that have ever existed, especially when the application is undergoing rapid change. But you can get the same effect, albeit less efficiently, by migrating the format of historical data to the latest version before loading it, if you have data migration scripts from version to version.
So being forced to address format migration early in development saved my bacon. I was able to use the migration module to upgrade each revision to the latest format in temporary storage and load it from there with the current persistence layer. The rest of the tool was completely unaware of old versions.